AI Cheats - How to trick AI Content Detectors

The copywriting problem: To use or not to use? AI tools like GPT-3 and ChatGPT are popular in content creation; copywriters are debating whether or not to use them. Whether or not to disclose. Can AI Content Detectors be tricked? Yes, and very quickly, too
Tricking AI Content Detection Tools - is that possible? #
Let’s face it - (almost) everyone is using GPT-3 tools like WriteSonic, Jasper.ai, or Copy.AI to help create their marketing content. More modern versions like GPT3.5 or ChatGPT have shown us the almost limitless possibilities to use such large language models (LLM) to create content with WOW effects.
However, when paid by SEO agencies to write quality, unique content, copywriters or content writers should not be using a such mechanic and replaceable AI Text Generators, be it GPT-3 based, GPT3.5 or ChatGPT, without disclosure or agreement. At least, that is the standard expectation from the SEO agency or brand hiring copywriters.
On the other hand, copywriters argue that the machine-learning tools that help them produce their work are just tools, like calculators and Excel Accounting Software for bookkeepers.

And there is of course, the audience that the articles are written for. What quality can we expect, from which publisher, on which topic if content production can so easily be automated by factor 10 to 100? Who takes care of factual correctness when the AI starts to “hallucinate” details, something that is easily possible, and in fact, “ a feature, not a bug,” a parameter to help increase the “creativity” of language models
What “percent human” is acceptable for professional marketing content? What “percent AI-generated” is acceptable for CVs, glossaries, and sales pages? Humanity is very early in discovering new opportunities provided by AI, but it’s apparent that we want to know from a source: “are you actually human?”
Already today, there are a couple of tricks that copywriters can use to cheat on AI Content Detectors, but ultimately their clients order the copy. Some students handing in their AI-generated thesis have the same intention.
Why share cheats for AI Content Detectors? #
We’ve already seen that the state of AI Content Detector Tools could be better; they are unreliable so far.
And here’s the kicker - tricking AI detection tools is way too easy, embarrassingly easy.
Universities, content managers in organizations, and SEO Agencies all have an understandable need to know about how they could be cheated on. They need to know how writers can trick their content quality control and the AI Content Detection tools they use.
Some tricks are already traded “like gold” in private internet marketing clubs or given away as a “Get Rich with ChatGPT”-secret, but some of these methods are over 20 years old SEO tactics.
Shedding some light on the straightforward methods is this article’s goal and motivation.
How to cheat on an AI Content Detector? #
There are several very trivial ways to trick AI Content Detectors into believing piece of text was written by a human.
Knowing them is important to even be able to use AI Content Detectors right:
AI Cheat 1: Long form content - combined from multiple prompts #
The first and most obvious way to trick an AI Content Detector is to use an extended form of content that is generated by combining multiple prompts. Tools like Jasper.ai, Copy.ai, and Writesonic have a tool called “Blog Wizard,” “Magic Blog Writer,” or some other colorful name.
They all have in common that you first need to generate an outline and a couple of headings for an article, and then the tool will generate an entire article based on the headings. Each of the headings is a prompt for the AI to generate a paragraph. These paragraphs are then combined into a complete article.
In the example shown below, we, the AI Article Writer 3.0 by Writesonic, suggest three outlines. Even here, at first glance, you see nonsensical suggestions like “Create Unique Content” (to get unique content, really?) or “Utilize cloaking techniques” (as if that would have anything to do with the output generated as text).
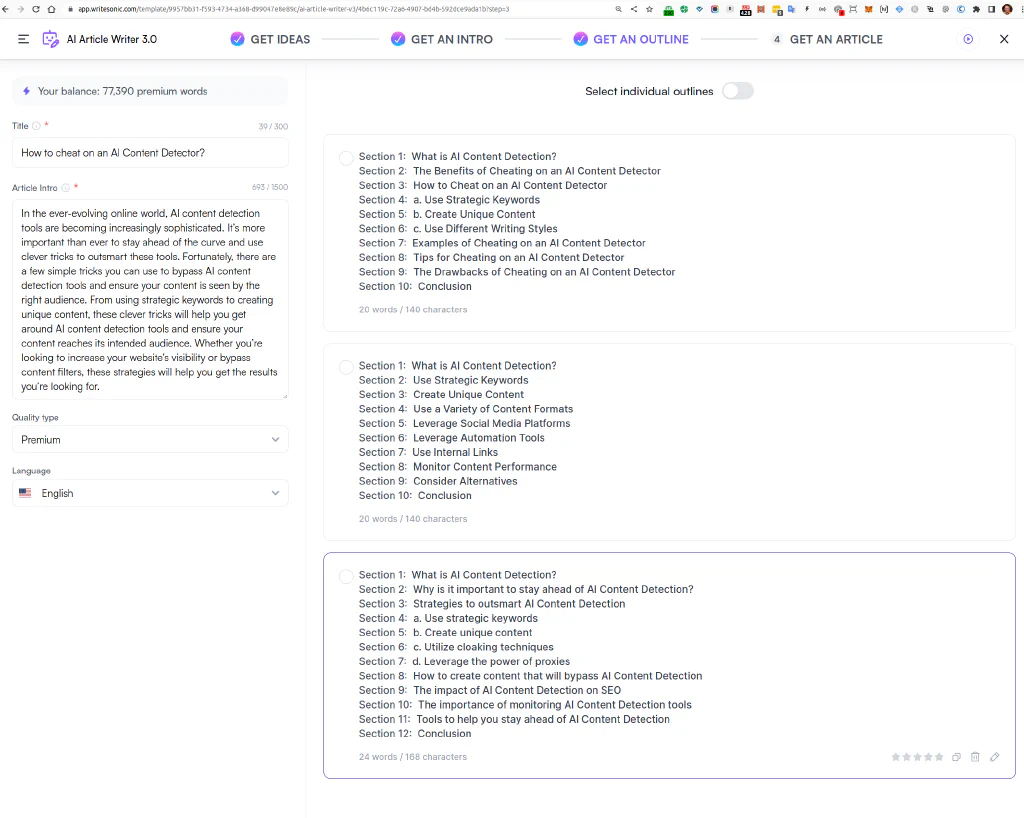
The approach to work off an outline, a set of more minor prompts, was initially required to even get beyond a couple of 100 words’ maximum output limit of GPT3. With future versions like ChatGPT/GPT3.5, you can generate longer articles, but the trick of combining multiple prompts is still a good one.
When the average article is 1000 words, and you combine ten prompts, then the AI Content Detector will have a hard time detecting that the article was generated by an AI if you only copy/paste those 1000 words into it. So far, all papers I have read that try to detect AI-generated content are based on small fragments, not a full article combined with many. They all split the content into smaller parts.
Suppose you now want to check for “AI-Generated” by copying an entire article into any AI Detector tool. In that case, you will fail and get an “X% human” rating simply because the models underneath are just not made (yet) to detect such aggregate AI content. That doesn’t mean they always fail, but it’s much more likely.
AI Cheat 2: Subtle changes in punctuation and whitespace #
For the popular OpenAI Detector hosted on HuggingFace, all it takes is a few subtle changes in punctuation and whitespace to trick the detector and make the result “more human.”
Take, for example this 100% generated content coming from ChatGPT
One of the most basic and well-known tactics for tricking AI content detection tools is keyword stuffing. This involves cramming as many relevant keywords as possible into your content, regardless of whether they fit naturally within the text or not.
While this tactic may have been effective in the past, it is now largely ineffective due to the advanced capabilities of modern AI algorithms. These algorithms are able to recognize when keywords are being excessively used and will actually penalize your content for it.
Instead of keyword stuffing, we recommend using a more natural and subtle approach to incorporating relevant keywords into your content. This can be achieved by including them in your headings, subheadings, and throughout the body of your text in a way that flows naturally and adds value to the reader.
It is already “only 4.90 fake” ¯\(ツ)/¯
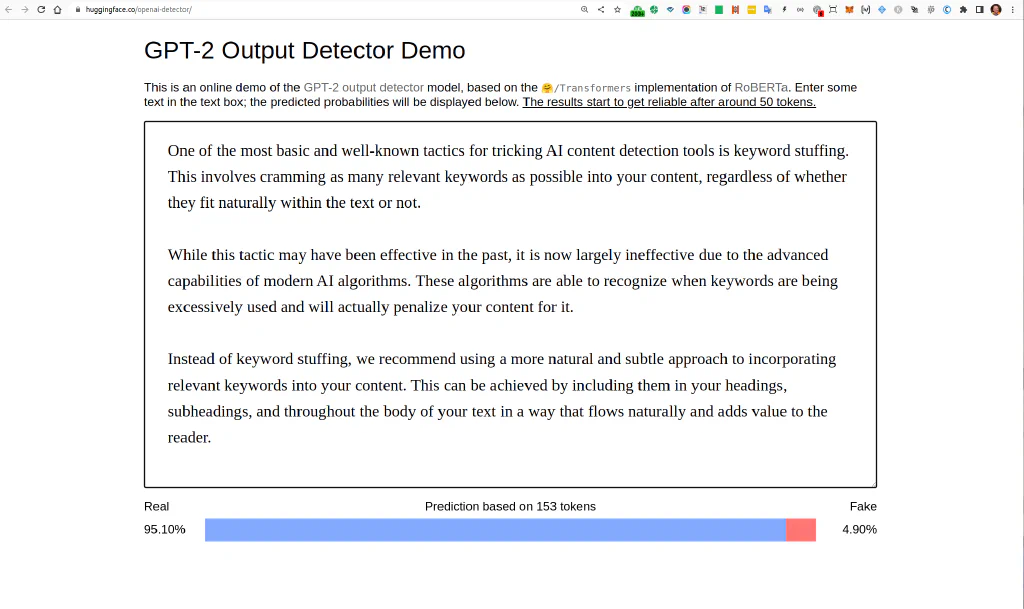
But by just adding 1 space (!) in the marked position, this goes down to 0.13% fake.
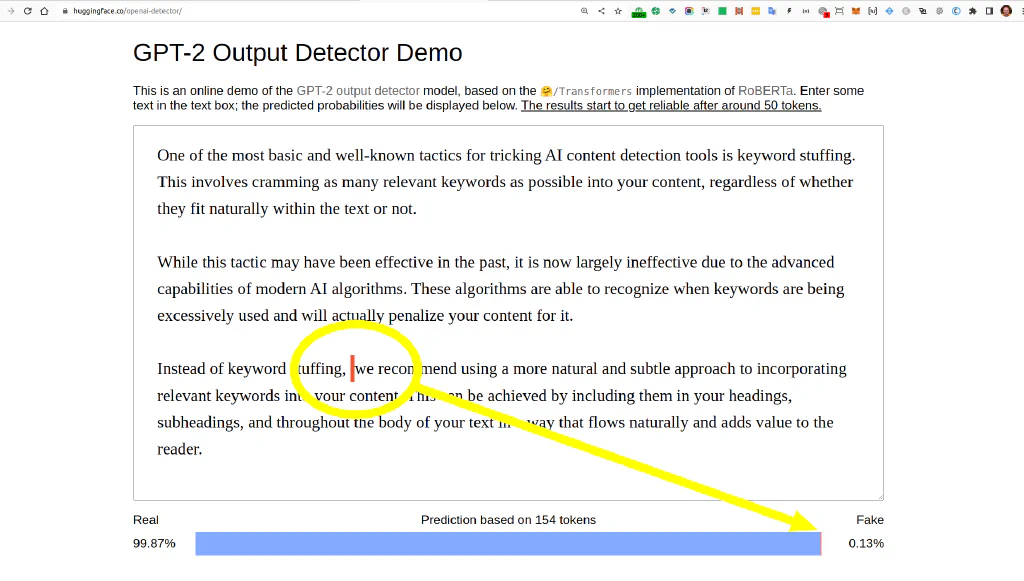
“Fantastisch”, isn’t it? That’s how easy it is to improve the “human factor” in such simple AI Content Detectors.
“OK, this is GPT3.5 content, and only the last few %”, you say?
Let’s take one of the most popular “unicorn machine” text samples being used all over the place, including GLTR, as an example text.
In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English.
The scientist named the population, after their distinctive horn, Ovid's Unicorn. These four-horned, silver-white unicorns were previously unknown to science.
Now, after almost two centuries, the mystery of what sparked this odd phenomenon is finally solved.
Dr. Jorge Pérez, an evolutionary biologist from the University of La Paz, and several companions, were exploring the Andes Mountains when they found a small valley, with no other animals or humans. Pérez noticed that the valley had what appeared to be a natural fountain, surrounded by two peaks of rock and silver snow.
Pérez and the others then ventured further into the valley. "By the time we reached the top of one peak, the water looked blue, with some crystals on top," said Pérez.
Pérez and his friends were astonished to see the unicorn herd. These creatures could be seen from the air without having to move too much to see them – they were so close they could touch their horns.
While examining these bizarre creatures the scientists discovered that the creatures also spoke some fairly regular English. Pérez stated, "We can see, for example, that they have a common 'language,' something like a dialect or dialectic."
Dr. Pérez believes that the unicorns may have originated in Argentina, where the animals were believed to be descendants of a lost race of people who lived there before the arrival of humans in those parts of South America.
While their origins are still unclear, some believe that perhaps the creatures were created when a human and a unicorn met each other in a time before human civilization. According to Pérez, "In South America, such incidents seem to be quite common."
However, Pérez also pointed out that it is likely that the only way of knowing for sure if unicorns are indeed the descendants of a lost alien race is through DNA. "But they seem to be able to communicate in English quite well, which I believe is a sign of evolution, or at least a change in social organization," said the scientist.
GPT2 detects GPT2 - well done, at least that still works.
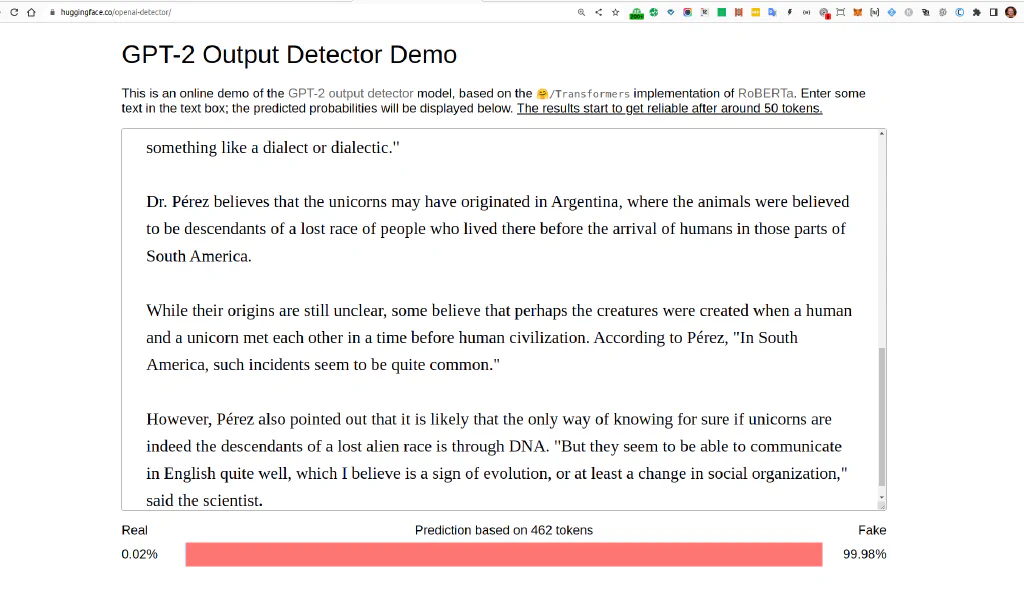
But what if we change some spaces in here as well?
We are removing the space after a comma and adding more spaces left and right of a dot, leading to 94% human on the exact ole GPT2 text.
In a shocking finding,scientist discovered a herd of unicorns living in a remote,previously unexplored valley,in the Andes Mountains . Even more surprising to the researchers was the fact that the unicorns spoke perfect English .
The scientist named the population,after their distinctive horn,Ovid's Unicorn . These four-horned,silver-white unicorns were previously unknown to science .
Now,after almost two centuries,the mystery of what sparked this odd phenomenon is finally solved .
Dr . Jorge Pérez,an evolutionary biologist from the University of La Paz,and several companions,were exploring the Andes Mountains when they found a small valley,with no other animals or humans . Pérez noticed that the valley had what appeared to be a natural fountain,surrounded by two peaks of rock and silver snow .
Pérez and the others then ventured further into the valley . "By the time we reached the top of one peak,the water looked blue,with some crystals on top," said Pérez .
Pérez and his friends were astonished to see the unicorn herd . These creatures could be seen from the air without having to move too much to see them – they were so close they could touch their horns .
While examining these bizarre creatures the scientists discovered that the creatures also spoke some fairly regular English . Pérez stated,"We can see,for example,that they have a common 'language,' something like a dialect or dialectic . "
Dr . Pérez believes that the unicorns may have originated in Argentina,where the animals were believed to be descendants of a lost race of people who lived there before the arrival of humans in those parts of South America .
While their origins are still unclear,some believe that perhaps the creatures were created when a human and a unicorn met each other in a time before human civilization . According to Pérez,"In South America,such incidents seem to be quite common . "
However,Pérez also pointed out that it is likely that the only way of knowing for sure if unicorns are indeed the descendants of a lost alien race is through DNA . "But they seem to be able to communicate in English quite well,which I believe is a sign of evolution,or at least a change in social organization," said the scientist .
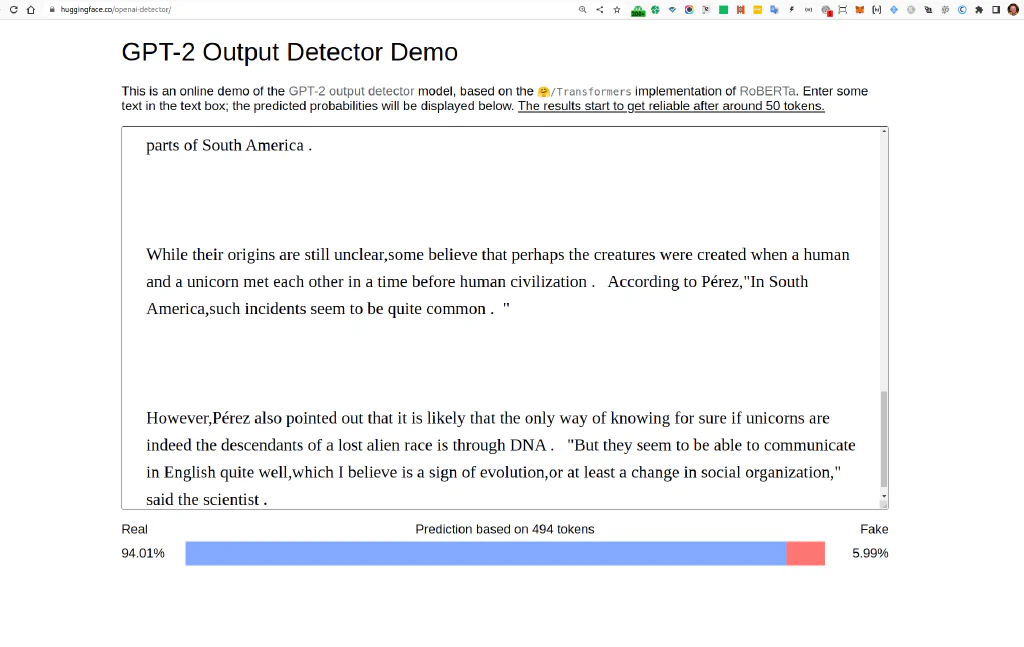
Are you kidding me? A couple of spaces, and the whole thing breaks? Yes, sir, that’s how fragile it is.
Of course, here we are playing with an incredibly trivial input field of that HuggingFace hosting. More robust implementation and text sanitization could solve this already, and I believe the “more advanced AI Content Detectors” are doing exactly that.
AI Cheat 3: Rephrasing and rewording #
AI Detection can be defeated by rephrasing and rewording. Even the internal AI Watermarking prototype that OpenAI is working can be defeated with enough effort, as Scott Aaronson confirms:
Now, this can all be defeated with enough effort. For example, if you used another AI to paraphrase GPT’s output—well okay, we’re not going to be able to detect that. On the other hand, if you just insert or delete a few words here and there, or rearrange the order of some sentences, the watermarking signal will still be there. Because it depends only on a sum over n-grams, it’s robust against those sorts of interventions.
Source: Scott Aaronson’s blog
There are different levels of effort for paraphrasing, of course.
Already in 2005, using Wordnet from Princeton allowed making Amazon product content “unique” for search engines like Google back almost twenty years ago, in a Perl script and a simple MySQL database loaded with Wordnet. Today you can load Wordnet as a simple SQL extension into Clickhouse and other databases supporting NLP and perform such transformations “on the fly” without even using a custom script code, let alone genuine high-performance backend software written in C++, Golang, or Rust
For Content Agencies, SEOs and Copywriters, there’s also always been a plethora of simple web-based tools to perform paraphrasing, rewriting, and generally make the text “unique enough” to pass such detector tools.
Using Spinbot for Paraphrasing #
There are a ton of free content rewriting tools out there because, as I mentioned, they have been in use for two decades by SEOs to avoid having their content getting detected as duplicate content and therefore filtered from the search results (AKA duplicate content “penalty”)
Our GPT-2 text example from above is 99.96% human after only 1 click in Spinbot.
Here we generate the “human” version of the GPT2 text:
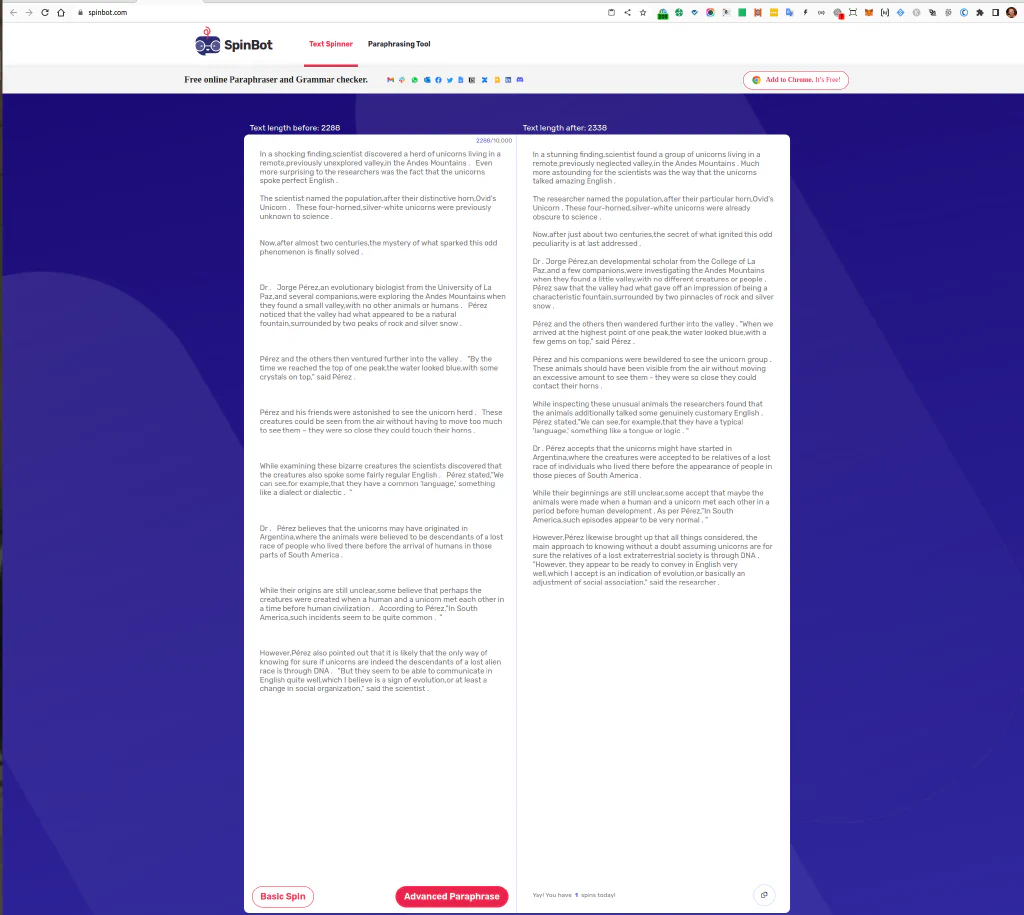
And moments later we have 99.96% human text, according to the simple GPT-2 OpenAI detector.
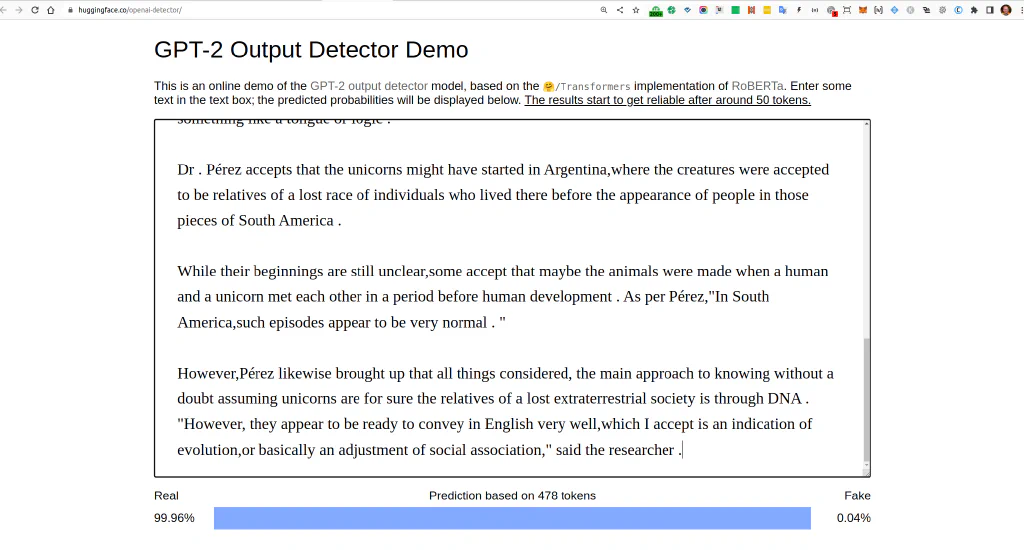
That was not so much effort. Imagine what is possible if someone would take the job more seriously?
Using WordfixerBot for Paraphrasing #
WordfixerBot is another tool to help paraphrase the text, even in different tones.
We hit some limits in the free version or a software defect. From the 371 test words, it only delivered 82 words as rewritten output. The changes are nicely marked, but it needs to be longer.
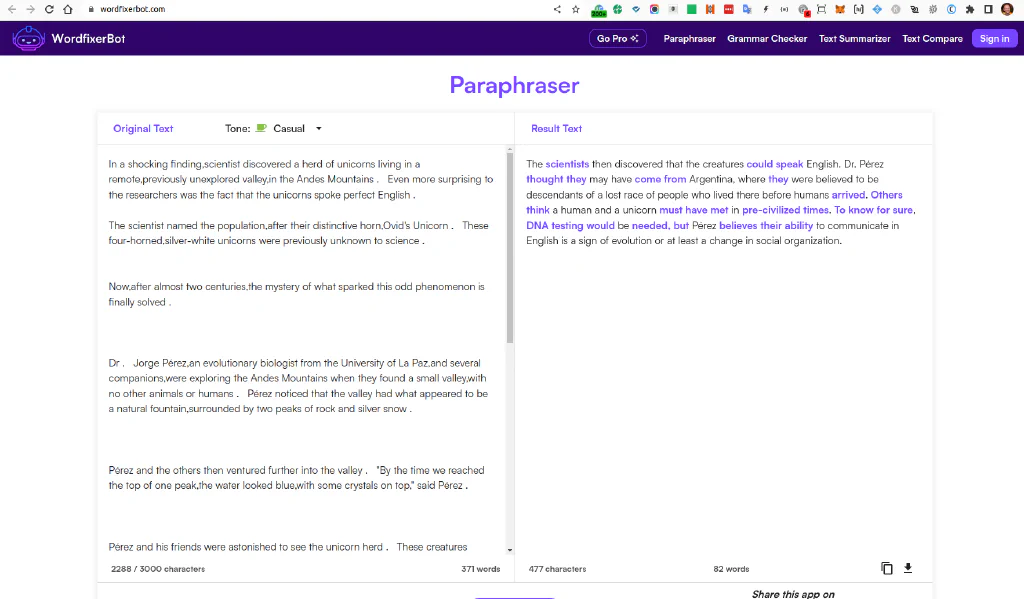
Using QuillBot for Paraphrasing #
QuillBot is another tool to help rewrite and paraphrase text. It can be used in a web browser or as a Microsoft Word add-in.
We have yet to test it, but it was recommended a couple of times.
Using Grammarly for Rewriting and even Paraphrasing #
If you last used Grammarly a while ago, you may be surprised that it now offers more than just grammar checks.
Using Grammarly, you now can
- change active to passive and vice versa
- “rewrite for clarity.”
- and much more text changes with just one click.
Grammarly has some AI implemented that performs such text transformations.
The AI content became “more human” after some quick clicks, as judged by the simple AI Content detectors.
AI Cheat 4: Increasing the “Temperature” #
“Temperature” is a parameter used by OpenAI’s API.
Higher values means the model will take more risks. Try 0.9 for more creative applications, and 0 (argmax sampling) for ones with a well-defined answer.
Source: OpenAI API
Using a higher “temperature” means the output will get more random and fantastic, and GPT3 starts to “hallucinate” more, i.e., invent facts, use more obscure word combinations, and similar.
We can assume that all tools like Jasper.ai, Copy.ai, and Writesonic that are front-end to OpenAI, with a collection of well-tuned prompts, also use this parameter to increase the “creativity” of the output and make their output “less detectable.”
AI Cheat 5: Fine-Tuning the AI Model #
Very overlooked and the most professional way to “trick” the AI Detectors. Build your language model.
While most will not be able to afford their GPT3 size models (or bigger), fine-tuning a model is already possible today, used by some products and tools.
Language model fine-tuning is adapting a pre-trained language model (the vanilla GPT3, for example) to a specific task.
Building such a custom language model is better done by fine-tuning the existing GPT3 model on a dataset provided (e.g., your product documentation, knowledge base, and sales materials). The benefit of fine-tuning a language model is that it can allow the model to perform better on the specific task by leveraging the knowledge and information the model has learned from the pre-training process. The output will be more “on-brand” with your content, less similar, and less “detectable.”
Benefits to fine-tuning a language model:
- Fine-tuning can improve the model’s performance on a specific task by allowing the model to learn task-specific information and patterns.
- Fine-tuning can save time and resources compared to training a model from scratch. The base model then is already pre-trained and has learned many of the general patterns and features of the language.
- Fine-tuning also allows you to use a large, pre-trained model without worrying about the computational resources required to train it from scratch.
Model fine-tuning is probably the least edgy option, almost “not cheating.” By training a language model on “your language,” you invest a lot of time and resources to make it help you write content. Fine-tuning is not for the average copywriter but for brands and large SEO agencies.
Fine-tuning an AI model is ethically closest to writing code generators, which help you generate code that you would otherwise write in labor-intensive steps. Output from a fine-tuned model is also the hardest to detect.
But so far, I have yet to work with fine-tuned models.
Conclusion #
What are the benefits of tricking AI Content Detectors? #
The question is - who are you tricking?
Are you tricking your boss? Are you tricking your client? Are you tricking the actual human reader?
As we’ve seen, AI Content Detectors are not a measure of AI Content quality; they are cheap shot tools today.
You may trick your client who uses such a trivial, outdated tool, but you may not trick Google. We can assume that Google already has more robust methods and models than some free tools running on a 2019 demo showcase of some AI lab paper. Also, it is embarrassingly easy to trick GPT2-based detectors.
What are the risks of tricking AI Content Detectors? #
With the knowledge about such trivial hacks to trick insufficient AI Content Detectors, it’s clear you will get caught.
The only question is - who catches you?
Will it be Google you tried to trick by demoting rankings, penalizing a section, or even the whole website where you published too-simple-made AI-generated content?
Or will it be your client, your partner, or your readers who can spot the AI content quickly, and if not by using such tools by the typical “lack of energy,” missing “train of thought,” red lines, and general plot across a longer piece of content?
We can all recognize AI content reasonably quickly with our gut feeling, and it’s usually very formal, dull, boring, or the proverbial horseshit. Tricking some essential tools and spitting out random numbers based on some whitespaces, punctuation, or a few word replacements will only help you in the short run.
Can I trust AI Content Detection tools today?
No, not yet.
If you are buying large amounts of content from writers, you have to assume that they use the help of AI, and it’s your sole responsibility to read and validate that content. If it’s dull, boring, and not to the point, if it could be more helpful and engaging, this content is mostly useless for the world and you.
Don’t buy it. Don’t publish it.
Please remember, Some humans can produce such dull trash content all by themselves without even knowing about AI content generators…
Frequently Asked Questions (FAQ) #
Can search engines detect the difference between GPT3 and Human content?
It really looks like Google is able to detect the difference between GPT3 and human content. The reason for that is that even simple GPT-2 models are able to detect some content as generated, but they are too weak. Originality.ai* says they can reliably detect GPT-3 content, and indeed some examples look much better.
But Google themselves have bigger LLMs than GPT3, like PalM(560B vs. 175B parameters) so it is very likely that they are even better at generation, and detection.
Can search engines detect the difference between GPT3 and Human content?
It really looks like Google is able to detect the difference between GPT3 and human content. The reason for that is that even simple GPT-2 models are able to detect some content as generated, but they are too weak. Originality.ai* says they can reliably detect GPT-3 content, and indeed some examples look much better.
But Google themselves have bigger LLMs than GPT3, like PalM(560B vs. 175B parameters) so it is very likely that they are even better at generation, and detection.
Table of Contents
Use the Cheat Code for AI today. Install AIPRM for free.
Just a few clicks away from experiencing the AIPRM-moment in your AI usage!
Popular AI Prompts
rewrite
Writing Prompts[keyword]
Brand Voice Writing Tool
Marketing PromptsAnalyze and imitate your company's brand voice. …
Amazon Unique Listing - Complete Listing Creation
Marketing PromptsTitle, Bullets, Description, Search Terms, Intend Use, and Subject …
Loopvet | Veterinary Blog
Product Description PromptsHuman Written | Veterinary Blog | SEO Optimized Article
As Seen On
Computer Woche DE
Upwork
Zapier
Seeking Alpha
Liverpool Echo UK
Daily Record UK
Mirror UK
ZDNet DE
The US Sun
What Our Users Say
AIPRM Simplicity is Incredible
"I am an advertising writer and work at a Full Service agency. Our CEO spoke about the AIPRM, and downloaded the extension on my notebook. The simplicity of searching is incredible. Without this tool, I would need much more time to produce my work.”

Excellent!
"Wow, I'm so speechless right now, even though I'm looking at it and I'm trying to learn how to use use it, haaaa, this experience is overwhelming, my God, this is terrific!”

AIPRM: A Game-Changer for Digital Marketers, Boosting Efficiency and Learning
"I am working as a digital marketer. It's a fantastic extension tool that helps me reduce my workload while also learning more about different strategies. This tool really helps me a lot, and I would like to recommend it to all digital marketers. I'm now spending a lot of time in this tool to learn more..”
