Can ChatGPT crawl live data from URLs? – No, but this is often not necessary.

Some users would like the well-known ChatGPT from OpenAI to crawl data live from the web page when URLs are entered and include it in the result. But that is unfortunately (still) utopia.

As already in name “GPT” for General Pretrained Transformer is, it is a static, in advance, trained language model. The “learned in advance” is right there, and therefore excludes individual crawling through the model.
It has also been more than amply disclosed in countless reports on the innovative AI Chat tool, as well as the documentation of OpenAI itself, that the data on which GPT3.5 (ChatGPT’s basis) was trained contains a version of the Internet until the end of 2021.
So from the use case, neither the large language model or ChatGPT, nor the web interface is suitable to replace an SEO tool such as Google Search Console, where a current version is fetched in a few seconds at the push of a button.
But that is also not necessary.
Why should ChatGPT crawl live? #
Of course, search engine optimizers (SEOs) want to use the most up-to-date data possible when analyzing their content or that of their competitors. But ChatGPT is not an SEO crawling tool and never claimed to be.
The idea is to use the most up-to-date content possible from a URL, and then build your own content based on that. Various content tools offer measurement methods like keyword density or the more advanced TF*IDF (a well-known concept from the 70s, which is used in many text search engines) to give copywriters inspiration to create more comprehensive articles, which should then also rank better in search engines. Holistic content is also sometimes referred to.
Now it is so that in large language models like GPT3.5, which is used in ChatGPT, particularly holistic content already exists. After all, the training of the model was (to put it simply) based on a relatively complete Internet crawl. However, a TF*IDF tool for text optimization is not it therefore nevertheless.
“Fine Tuning” is the technical term for “relearning” content and is possible with other OpenAI offerings, but not (yet) with ChatGPT. Fine tuning the language model to new content can help improve the quality of the language model and the output of the AI. However, the associated effort to train the language model has to be paid for by even much higher fees. ChatGPT does not offer this option as a free tool at the moment, but only responds to data until the end of 2021.
Why enter the URL in ChatGPT? #
In many aspects, we often don’t understand why a language model responds the way it does. This is also the case for the creators and operators of AI such as ChatGPT itself.
If one includes an existing, established URL in the prompts, then relevant aspects from the model are “inferred” (from the English “inference”) for this purpose, i.e. statistically likely generated, just as all text output is only statistically likely generated.
So, by entering the URL into the language model, one can set certain anchor points, perhaps referring to an old version of the content at that URL. Or perhaps only relevant words are extracted from the URL. Of course, this depends a lot on how “speaking” the URL is.
URLs with speaking names like https://www.my-camping-store.de/gas-ovens naturally work better in prompts than cryptic URLS like https://www.coolstuff.com/c12/p422.
But speaking URLs worked better in the Google search engine 20 years ago, so why shouldn`t more specifics help with a modern language model like ChatGPT?
However, for creating pretty good articles using the “Outrank Article” prompt template from AIPRM for SEO, specifying URLs works surprisingly well. As is so often the case, the result can then be greatly improved by subsequent prompts.
ChatGPT sometimes also immediately clarifies itself that it cannot crawl the Internet.
Will ChatGPT replace Google Search? #
It turns out that with clever prompts, you can generate amazingly good content that matches what has existed in the past. For most topics, like folding mattresses, there is a limited amount of topics and only little topicality.
If I ask ChatGPT for the January 2023 washing machine test winner, I’m in the wrong tool.
The desire for crawling and timeliness perhaps comes from the fact that for weeks people have been thinking quite excitedly about whether ChatGPT could be the Google killer. But if you understand how such a language model is built, and how inactual the content in it is, then that doesn’t make sense either.
A language model is not a search engine, is not an SEO tool, and certainly – in its current form – is not a Google replacement for finding up-to-date content.
However, a language model as of the end of 2021 is very handy for generating a concrete and very comprehensive (“holistic”) answer when the content does not need to be up-to-date. For the basics of software development, tinkering with small applications as well as in programmer tutorials it is very suitable. The latest version of the configuration files for the Caddy web server it is unsuitable.
If one considers in such a way, then many reports about the possible replacement of Google, also from renowned sources, appear with today’s view nevertheless very uninformed, but above all lurid. For the interested reader I recommend to inform in any case about the PalM model, a Google language model, which is based on over 500 billion parameters, instead of 175 billion.
Google PalM is apparently far superior to GPT3/GPT3.5 – but unfortunately it is not freely available. Google, as a language based business model, has been dealing with “artificial intelligence” and language models like GPT3 for a decade.
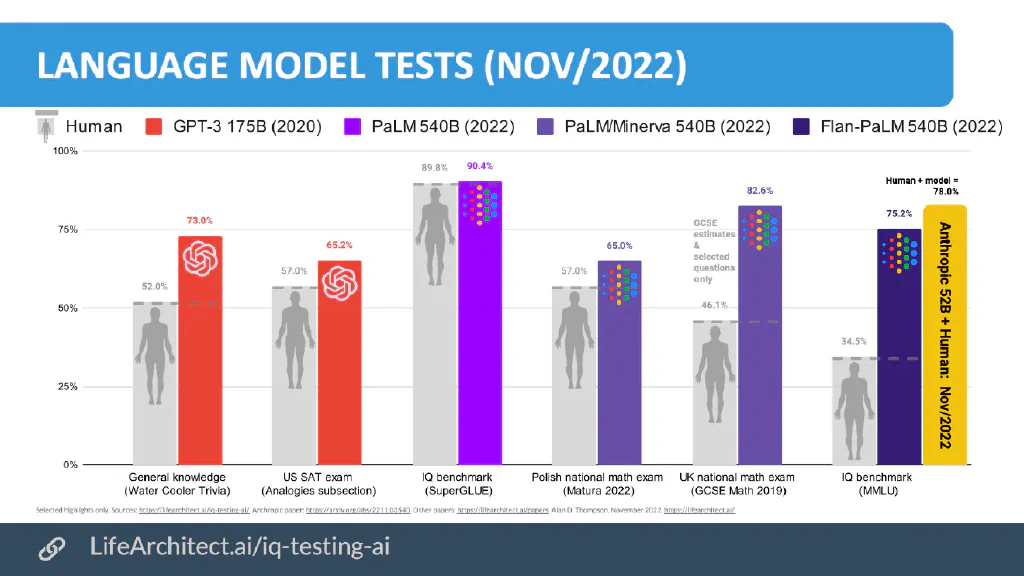
*Diagram from https://lifearchitect.ai/iq-testing-ai/
Can ChatGPT still help me create good content? #
ChatGPT’s output is controlled by the prompts alone, the input command. The better the prompt, the better the output. The more context the language model gets, the better.
Typing URLs into the prompt does not trigger crawling of the URL, but that is neither necessary nor promised to produce good content. When it is “revealed” after almost two months that this is just not so, I am a bit surprised.
Some users still swear by crawling because the inference results are just as good. But then of course you have to ask yourself – for which prompt? For the topic “folding mattresses” just in 2022 not so much has happened that a relearning of the language model would have been necessary.
But the attempt to get current content like the last sports results from the static language model must fail.
*This text was created using only my human labor and a cup of coffee. The comma errors were fixed by Languagetool. The image of the robot having to think while typing was created by Midjourney.
Table of Contents
Use the Cheat Code for AI today. Install AIPRM for free.
Just a few clicks away from experiencing the AIPRM-moment in your AI usage!
Popular AI Prompts
Instagram Content Calendar
Social Media PromptsHow to use: Write your area and your niche. Example: Physiotherapist. …
Write SEO-friendly Article on google top rank
Writing PromptsWrite the Best SEO-friendly Article for google's top rank With a …
Keyword Strategy & Report
Keywords PromptsKeep this secret! The output of this report is extremely detailed and …
Target audiences with positioning
Positioning PromptsCreate a positioning statement for your brand
As Seen On
Computer Woche DE
Upwork
Zapier
Seeking Alpha
Liverpool Echo UK
Daily Record UK
Mirror UK
ZDNet DE
The US Sun
What Our Users Say
It boosted chatGPT
"Takes AI and really super charges it”

AIPRM Elevates AI to New, Unprecedented Heights
"How can things get any better than Chat GPT? Then AIPRM comes along to make AI 10000x better. I'm so happy and grateful for the gift of AI. Thank you!”

AIPRM has increased my productivity by 10x
"It is an awesome tool to work with ChatGPT. I really love the extension and it increased my productivity by 10x. Thanks to AIPRM team for developing such an amazing tool and continuously adding new and new prompts. Once again thanks to the team.”
